Consulting, Microsoft Dynamics AX
Troubleshooting Dynamics AX Performance Part 1A: Dynamics AX 2012 Table Relations
 16411
16411 
Feb
It’s time to finish this blog series on performance, and I have one month to get 8 posts out. Please forgive this instructor. Things have been a little busy lately. So, tonight, I was reading over a course and thought of writing this blog post. One thing that I love about being an instructor is the understanding that comes from teaching a course multiple times. It really helps to put things in perspective as you often teach what you also consult over. When I first started, I thought of relations like everyone else – as the form helpers that really aid in being able to create nice forms that update and provide data from multiple tables.
But little did I realize, that with this one little step, I made one of the most important data retrieval decisions in my entire Dynamics AX setup. See table relations govern index creation and query execution plan behavior. Stuff will start timing out and people will start complaining when this is set up wrong. Forms will hang on loading, for example. So, you need to know how to deal with this. Aww…. The irony.. It’s always the 5 minute decision that turns out to be one of the most important ones of all. That rule is so true here.
Background: In SQL Server, we have the concept of “constraints,” which give us the ability to dictate how and which data can be added to tables. We also have this concept of lookup tables where we can store values to be used for populating other tables. In Dynamics AX, we have relations, which can act like a lookup table or a constraints, and they take it one step further: they give us the ability to display data in forms and have a HUGE, DIRECT effect on query generation.
Please keep in mind that some of these constraints have a tendency to cause certain query behavior in SQL. I detail those similarities here. But these are not the actual SQL Operations when you create these operations. However, you will see certain types of operations performed on lookups which resemble these analogies. To summarize, there are 4 types of relations that we think about and these are the summaries of my two to three part performance subseries(haven’t decided how long yet):
| Type of Relation | Definition | Like which SQL Operation (not actual) | When to use |
| Normal | When you specify that one table can use columns in another table because of some way that the records are related. | Inner Join. With large tables, you will often see another process happening called a … shhhhh.. “hash join.” Poor little SQL Server is struggling to turn poor performance tuning into something special. Unfortunately, it is like giving a good quarterback poor wide receivers in football. He’ll look bad just as SQL does when this isn’t set up right. | Best used between two smaller tables. Doing this with big tables like many people do when they do that little lookup operation in the Dynamics AX window is performance suicide – which is why many end users are shocked when their Excel documents fail to load. Oh, if only they knew, the backend was set up wrong to begin with. The exception to this is a properly indexed Dynamics AX lookup. A properly indexed lookup will disrupt the whole heinous mechanism when trying to do this with large result sets. (hint: sort the columns that you prefer the lookup on!) |
| Field Fixed | Sounds complicated but I plan on doing a demonstration of it later – it will make sense. For now, when you make this sort of relation on a table, it won’t show any data in a column that is not in the “related table” that you specified. | A join with a where clause on it and an “exists” statement. A logical Check Constraint.. | This is highly preferable when dealing with one large table and one small table or small number of unique values in an indexed column on a large table. It is also very fast(when setup right). See SQL has this little habit of taking the table with a smaller result set (aka dataset) and storing it in the ram of the server. It then iterates over each and every member of the larger Table to find matches. The process is usually very fast provided that one of the result sets is small(also known as the enum in Dynamics AX). Use this when you have a few rows in one table going against rows in another, bigger table |
| Related Field Fixed | The table with the “many” is restricted based on values of the primary table. So, wait, you mean the foreign key column can’t show any values if those values don’t exist in the primary key column. Isn’t that a primary – foreign key relationship? Sort of, except that you didn’t explicitly create a primary foreign key constraint and that causes big differences. | A logical Check Constraint though I will show you how to determine that later for troubleshooting | This is also very beneficial as long as the primary table column has very few unique values or is exceptionally indexed. Everything about performance tuning in the field fixed option applies. You are in performance tuning heaven when you see a “lookup” operation in your sql plan with “index seeks” going on and one index seek involving a small amount of values. In other words, one column that has a small number of values versus a column from another table with a big number of values. |
| Foreign Key | This table has a foreign key which references a primary key of some other table. | A foreign key constraint that leads to inner joins with lookups | With two big tables this can also be problematic . Will perform better than a straight “normal” relationship because (contrary to popular belief) primary/foreign key relationships do help out with performance. But this no substitute for proper query optimization. |
First, set up the Demo Environment:
- Open up your developer workspace on the sample virtual machine available on PartnerSource. I am using the Dynamics AX 2012 VM, but after the performance series, and in the future, I’ll be using the Dynamics AX 2012R2 VM. There are too many benefits in Dynamics AX 2012R2 to ignore. It’s time to upgrade (especially for you programmers).
- Open up two instances of the AOT (by hitting CTRL+D)
-
Create an Extended Data Type (Extended Data Types allow for us to store existing data types with certain settings and call the existing data types with new settings by some name. This is very analogous to an ‘alias’ in SQL Server. For example, I name some 30 character string as “AccountNumber”. Now, when someone sees it, they will know that it represents AccountNumber. I didn’t have to call it “30 character string”) and call it DemoID.
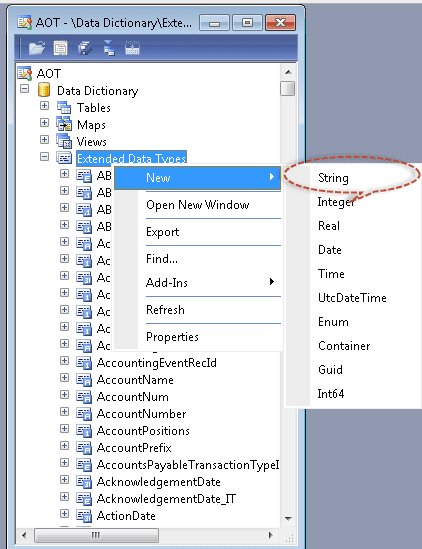
-
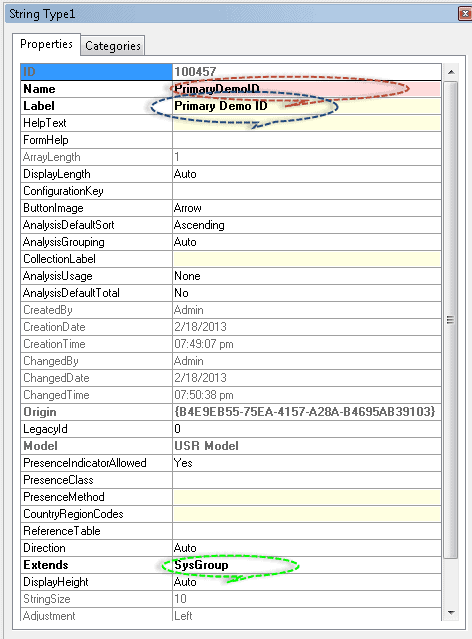
Now, turn around and alter 3 Properties in the properties window: Name: “PrimaryDemoID”, Label: “Primary Demo ID”, and Extends: “SysGroup”. This inherits from the basic built-in types and creates a string storing 10 characters. We can use this where we like.
-
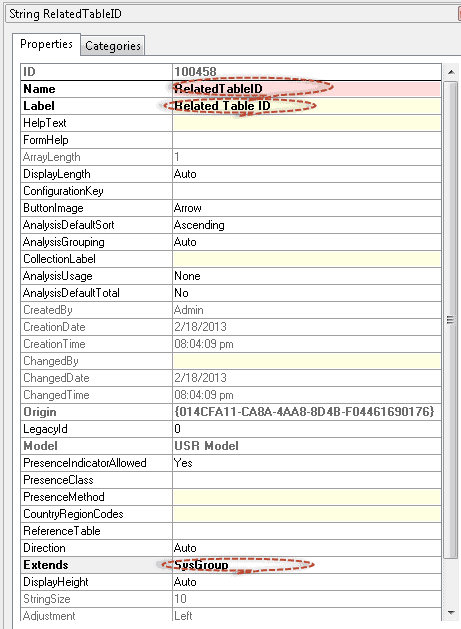
Repeat the process, but make an Extended Data Type with these settings: Name: “RelatedTableID”, Label: “Related Table ID”, Extends “SysGroup.
- Close the property sheet and save all your changes. You should be prompted to synchronize your tables with the database. Choose “yes” and let it finish synchronizing.
-
Now, let’s create two tables: once called “PrimaryTable” and the other called “RelatedTable”
-
Right click on the “Tables” node of the data dictionary, and click “new Table”
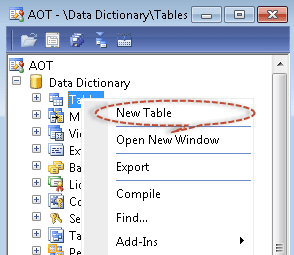
So, you only need to alter two settings for now:
-
Make Name: “PrimaryTable” for the first table. Make label “Primary Table” for the label.
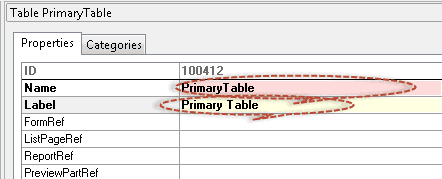
-
- Do the same thing for the second table except give it a Name:”RelatedTable” and a Label: “Related Table”
-
Now, make sure that you have two developer workspaces open(hit “Ctrl + D and drag the second toolbox over so you can see two of them). Expand “Extended Data Types” in the second workspace. Expand “PrimaryTable” in the first Workspace. Drag Name, Address, and PrimaryDemoID to the
“fields” node of the PrimaryTable. Do the same thing for the RelatedTable, but drag over the fields for “RelatedTableID, AddressCity, and Name.
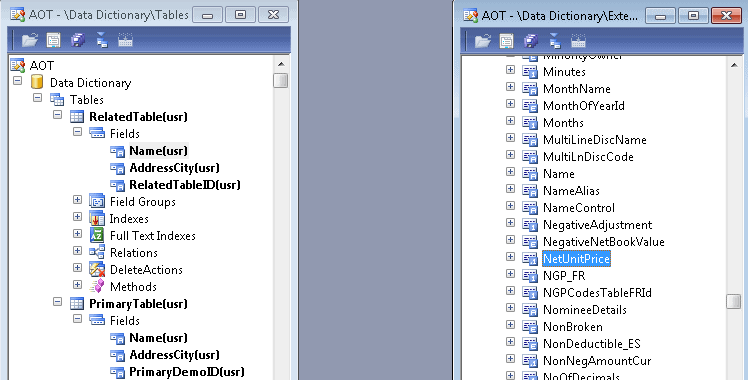
- Now, go back to your Data Dictionary, and expand the fields Node for both “RelatedTable” and “PrimaryTable”.
-
In the primary table, expand the “Fields” option and right click on “PrimaryDemoID”
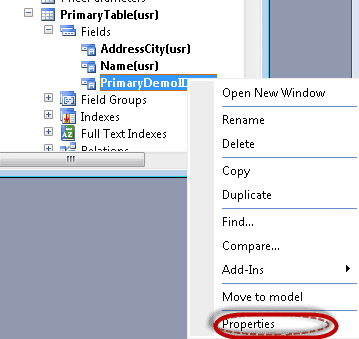
-
Once you are in the properties window, change the name to “PrimaryID” and the label to “Primary ID”. So that it looks like this.
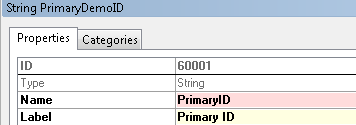
- Repeat the same process for RelatedTable, but change the RelatedTableID to “RelatedID” for name, and “Related ID” for label.
-
After you are done, close the properties box, and hit save everything (by hitting the little disk).
What did you just do?
Not much in regards to performance just yet. You created an Extended data type of the base type of string. You created two tables. You inherited from the extended data type. The goal here was to get the scenario setup so that we can begin to demonstrate what happens next and truly tinker with performance. That sets us up for Part 1B of the post . Remember, when it comes to understanding principles of performance and programming, there is no substitute for practice. You should try to do the demonstrations also. You can ask the many thousands of students that I’ve had in classes. I always insist that they get as much hands on work as possible. Most of them agree with me that this is the most effective approach. I promise to do Part 1B tomorrow no matter what or how much work I have to do!