Consulting, Dynamics AX Performance
Understanding the Most Common Cause of Poor Performance within AX and SQL
 10623
10623 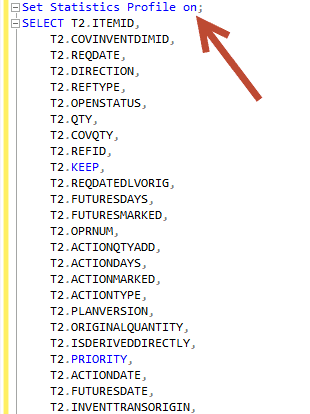
Aug
Let’s look at the most commonly misdiagnosed cause of poor SQL performance from my end. Years of experience and lots of implementations have taught me that the toughest part of being a Technical Architect is speaking up. One of the worst things you have to do as a Senior Technical Architect is warn a happy client that they are about to have severe performance problems. Responses can range from disappointed acceptance to outright hostility to even being dismissed off a project. See slowness rarely just happens suddenly as many like to believe. Usually, there are pretty strong indicators if one can just see the signs. And the signs are almost always there. In this post, let’s look at a common scenario that I’ve seen repeatedly misdiagnosed on the internet and in real-life, and see how to recognize and fix it.
CASE STUDY:
The client noticed that things just suddenly got slow. Suddenly AX started freezing multiple times during the day. Indeed, multiple SQL locks were occurring upon examining Activity Monitor. But volume had not increased – in other words, the number of users was constant and the users swore that this problem wasn’t happening 6 months ago. One other thing happened that was interesting, the DBA noticed that the problem was partially mitigated by running statistics or index rebuilds every few minutes. There have been no hardware changes during the last 6 months. Can you spot the problem?
WHAT IT IS NOT?
- Locks à No, locking and blocking are a symptom of the problem but not the actual cause
- Too many people on at one time – unlikely because the users had been relatively constant
- Hardware – unlikely, but possible because the hardware can malfunction or experience other issues
- Something else weird – usually you only see something weird when SQL shows no signs
- The Kernel – Kernel level errors usually don’t manifest as SQL locks and blocks. They typically result in long hangs on the AOS side or crashes
WHAT WAS IT?
Bad Query Plans. Let’s look at this in more depth.
First, to diagnose a bad query plan, you want to run one of the SQL queries that is going slow (finding it by using the AX Trace parser, SQL Events, SQL Profiler, some other software, etc).
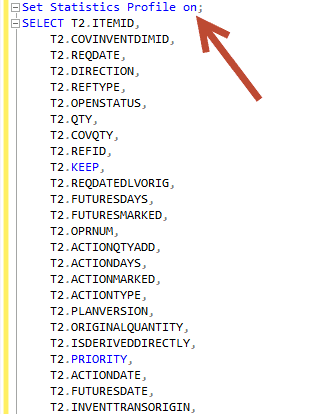
You want to run the “Set Statistics profile on” before you run it.
It will produce a real-life text output showing you the actual rows versus the estimated rows. But wait something is seriously wrong with the Release to Warehouse form. It’s estimating 1,285 rows but having to actually use 18 million rows for it’s spool operation. This is killing performance for Release to Warehouse with this customer. Not only that, the effect is so bad that it is actually bringing the entire enterprise implementation to a halt when 3 or 4 users try to use Release to Warehouse. How could the query plan be so wrong? It’s causing a lot of issues.

Of course, you see locks and blocks when stuff like this happens. Queries that take lots of minutes to run hold on to tables too long causing problematic locks. The mechanism of locking isn’t the problem, but it is the bad query plan.. This is extremely common.
Running the statistics plan can partially mitigate the problem but SQL performance still suffers because of the costs of having to excessively run statistic jobs.
Lets dig deeper and figure out why we are having the bad query plans and statistics. Not shown here is the fact that the query had a built-in, out of the box hint. Unfortunately, this is very common in AX. Many of the hints essentially force SQL to go into a nested loop algorithm which works fine as long as you have a small table to a big table. But in this case, the inventdim is not small for this client. Now, you have a very different situation, big table to big table. The forced algorithm has caused the SQL query to suffer. While this works great for smaller implementations and actually increases speed, it really slows down the big ones. Essentially, an implementation is punished for growing to a certain size because the query hints restrict SQL from being able to adapt it’s query plans to the new size.

Interesting, so a Kernel level hint on a form that can only be removed by essentially removing the form query and replacing it with a regular query is the cause of this on a standard AX form. It occurred on an InventDim that crossed one million records. A new implementation wouldn’t notice this sort of problem because they wouldn’t have enough records. An older implementation would notice it once it got enough data. An experienced performance tuner could see the problem pretty quickly by comparing the estimated and actual rows. Eventually, the discrepancy will show in problematic SQL performance.
How did I fix it?
Be a human.. I had two choices. I could either restrict the rows on InventDim to make it smaller by adding a query range or I could replace the form query with a regular query to turn off the hint and go through the painful process of completely remapping the query to the form to eliminate the hint. In this case, I just added a range for site to restrict the inventdim. That fixed the problem by restricting the records within InventDim per a site. Locking stopped and the query went to running in 2 seconds as the plan was aligned. The client was able to stop having to run statistics every 5 minutes and go back to running the job once a day with good performance.
In Summary
You’ve hopefully learned a very powerful tactic for diagnosing “sudden” poor SQL performance. They symptoms are not always the cause. Don’t assume that out of the box works for every case. Okay, that’s it for this post. Look very closely at this problem when you see an implementation having to excessively run index or statistics jobs to maintain performance. Just another day in the technical neighborhood…. Till the next time.